



















Annotating Malware Disassembly Functions Using Neural Machine Translation
Malware binaries may contain thousands to millions of executable instructions, and even expert-level reverse engineers can spend days analyzing disassembly to piece together code functionality. Iteratively annotating functions is one strategy that a malware analyst can use to break analysis down into more manageable chunks. However, annotation can be a tedious process that often results in inconsistent syntax and function choices among different analysts. The Mandiant Data Science (MDS) and FLARE teams released this blog post to accompany our recent NVIDIA GPU Technology Conference (GTC) presentation illustrating how we worked together to ease this burden through machine learning.
Highlights
|
Background: Static Malware Analysis with Disassembly and Decompilation
Basic static and dynamic analysis techniques can be useful for drawing preliminary leads during initial malware triage, but more in-depth analysis is required to get closer to malware authors’ intended objectives. A typical program will group related functionality into code constructs called functions, which will have either been written by a user or come from an existing library. Malware analysts and reverse engineers will skim through functions using a disassembler, such as NSA’s Ghidra or Hex-Rays’ IDA Pro, which generate low-level assembly language and higher-level, C-like pseudo-code. They will apply heuristics to annotate functions based on features like import usage, presence of specific assembly instructions, data references, and even graph structure. Annotating functions is an iterative process and an important step towards painting a more comprehensive picture of the malware’s overall functionality.
A malware analyst may revisit a single function several times during their analysis, updating an annotation each time. This can accumulate to a very long and tedious process. Professional disassembly tools can automatically recognize and annotate functions to reduce analyst effort during time-sensitive investigations. For instance, IDA utilizes mechanisms like FLIRT and Lumina to label previously identified function names, allowing annotations to be shared among users and across time. Unfortunately, such signatures can often fail to generalize to new samples and are not resistant to manipulation (e.g., different compile options). Signatures also only account for library code added by a compiler, leaving a large set of user-defined functions without annotations.
The three views displayed in Figure 1 represent a function that has been previously annotated as write_string. Figure 1A depicts the disassembly Control Flow Graph (CFG) view, where sequential assembly instructions are grouped into basic blocks represented as a directed graph. Edge arrows illustrate code execution paths from which coding constructs like a branch or loop can be determined. In Figure 1B, the decompiler renders the function from Figure 1A into a higher-level language that is more compact and easier to understand. Optimizations are applied to the disassembly as the decompiled output is generated, generally providing simplified pseudo-code. An Abstract Syntax Tree (AST) can be derived from the pseudo-code in Figure 1C where internal nodes represent programming language constructs and leaf nodes contain numeric and string data.
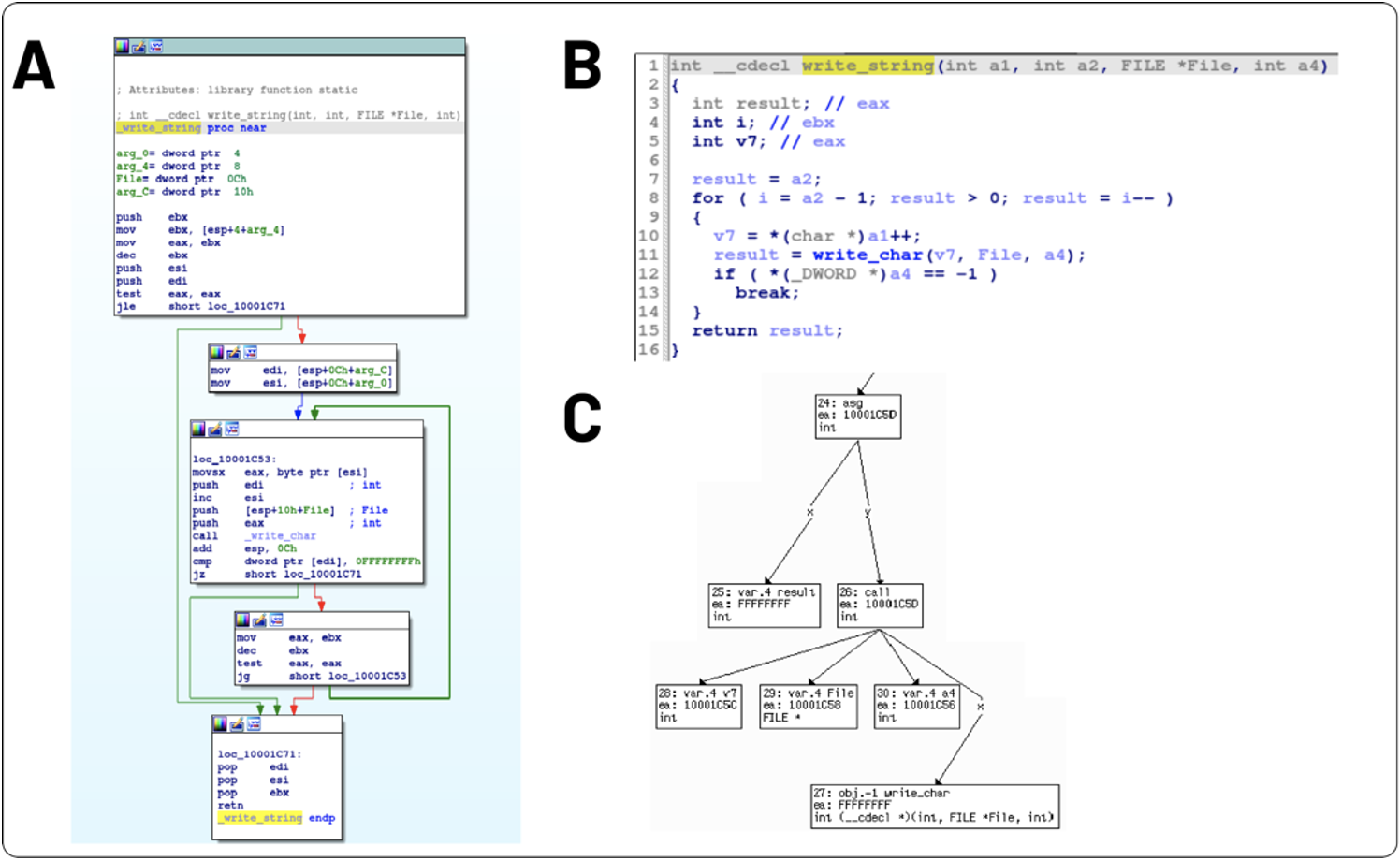
write_stringA reverse engineer will generally use views such as those present in Figure 1 to assist in making determinations of a function’s purpose. For example, the loop around write_char may imply that a series of characters is being printed. A series of characters may be a string, prompting the analyst to label this function as write_string. The capability of printing a string is generally not one an analyst is highly interested in. Unfortunately, time was spent reverse engineering this function that would have been better spent focusing on malicious capability. Additionally, decisions like which functions to annotate as well as what naming conventions to apply can vary widely from analyst to analyst. These set of challenges led us to ask the question: How can we improve function name coverage and standardize semantics within binary disassembly to accelerate malware triage?
Generating Natural Language from Source Code (and Vice-Versa)
By representing disassembly as a structured sequence of input tokens and corresponding ground truth function names as a sequence of target label tokens, we can frame this problem as a Neural Machine Translation (NMT) task. Seq2seq and large language modeling approaches have previously been applied towards generating natural language from source code and vice-versa. This includes use cases such as code summarization, code documentation, variable name prediction, and even auto-completion tasks (see OpenAI’s Codex model). However, these approaches mostly operate on higher-level programming languages like Python and Java that are more concise, easier to read, more linearly ordered, and syntactically richer than machine code.
To transform disassembly into inputs for an NMT model, we instead drew inspiration from previous work that generated sequences from structured representations of machine code. The first model, code2seq, represents code as a set of paths over its AST, whereas the second model, Nero, represents code as nodes and edges of a CFG. We trained our models on Windows Portable Executable (PE) files, which make up a large segment of the malware universe, unlike the Java and C# files used to train code2seq as well as the benign ELF executables used to train Nero.
Neural Representations of Decompilation ASTs
How did we adapt the code2seq architecture for malware function decompilation? Output from IDA’s decompiler is exposed to analysts via an AST (see Figure 1C). AST leaves encode user-defined code identifiers and names, while internal AST nodes encode structures like loops, expressions, and variable declarations. As with code2seq, we represented ASTs as random paths compressed to fixed-length vectors using a Bi-directional Long Short-Term Memory (BiLSTM) neural network layer and concatenated these path embeddings with AST leaf token embeddings during encoding. The model then attends to relevant AST paths during decoding to generate a sequence of annotation predictions. In contrast to code2seq, we embedded types and concatenated type embeddings alongside the leaf token embeddings and AST path embeddings.
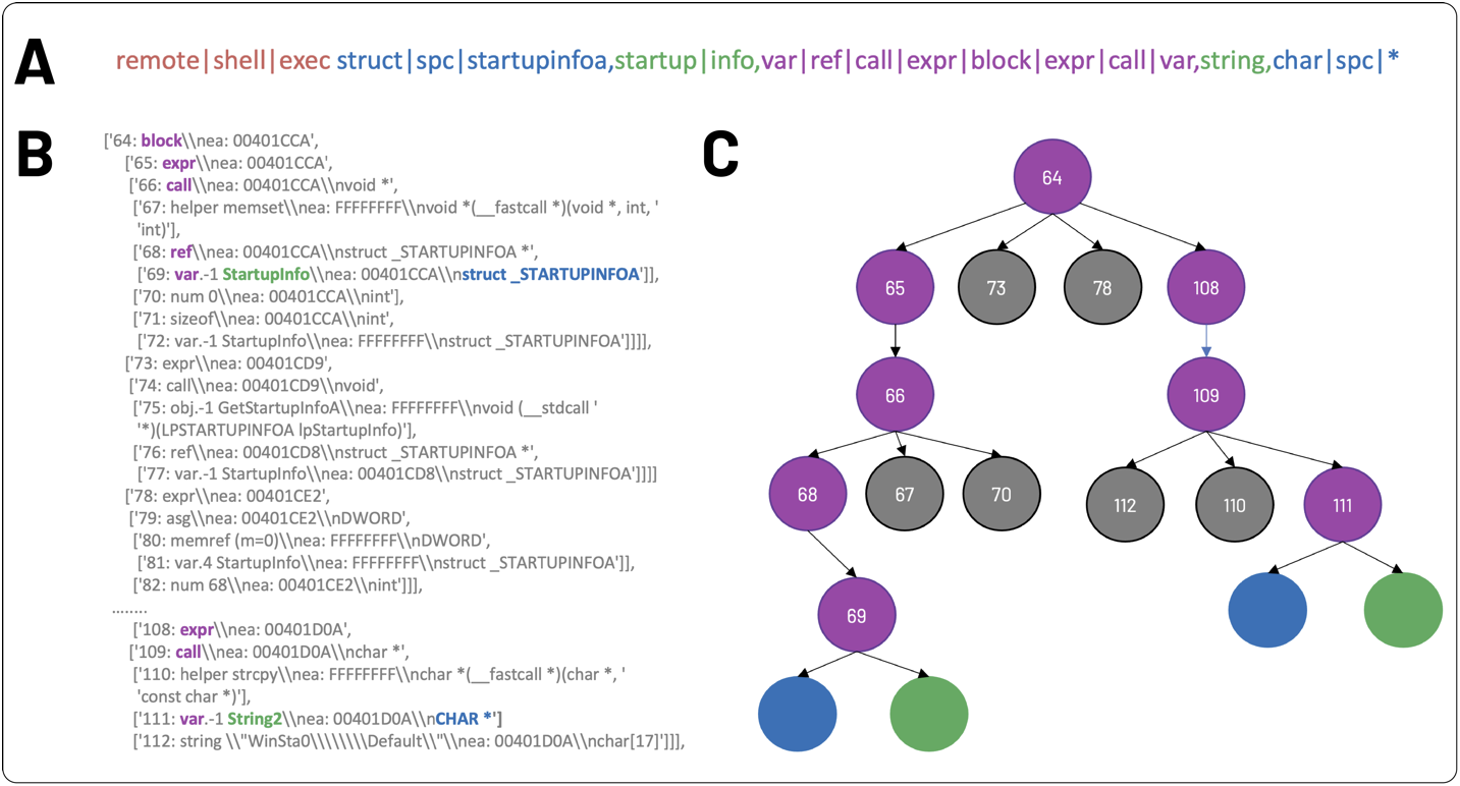
In Figure 2A, an example AST representation is comprised of label tokens (red), leaf value tokens (green), node paths (purple), and type tokens (blue). The AST path (purple from 2A) is highlighted within a snippet of decompilation in Figure 2B, where the sequence of purple node paths can be traced from the first leaf node (i.e. var on line 69) up the tree (i.e. ref on line 68, call on line 66, expr on line 65) until it hits the root node (i.e. block on line 64), before descending back down the tree (i.e. expr on line 108, call on line 109) until reaching this path’s other leaf node (i.e. var on line 111). Figure 2C shows the AST representation of the sampled path from 2A and 2B. Up to 200 such AST paths are sampled per function and processed sequentially by the BiLSTM, with corresponding leaf (green) and type (blue) tokens embedded separately prior to being concatenated during encoding.
Neural Representations of Disassembly CFGs
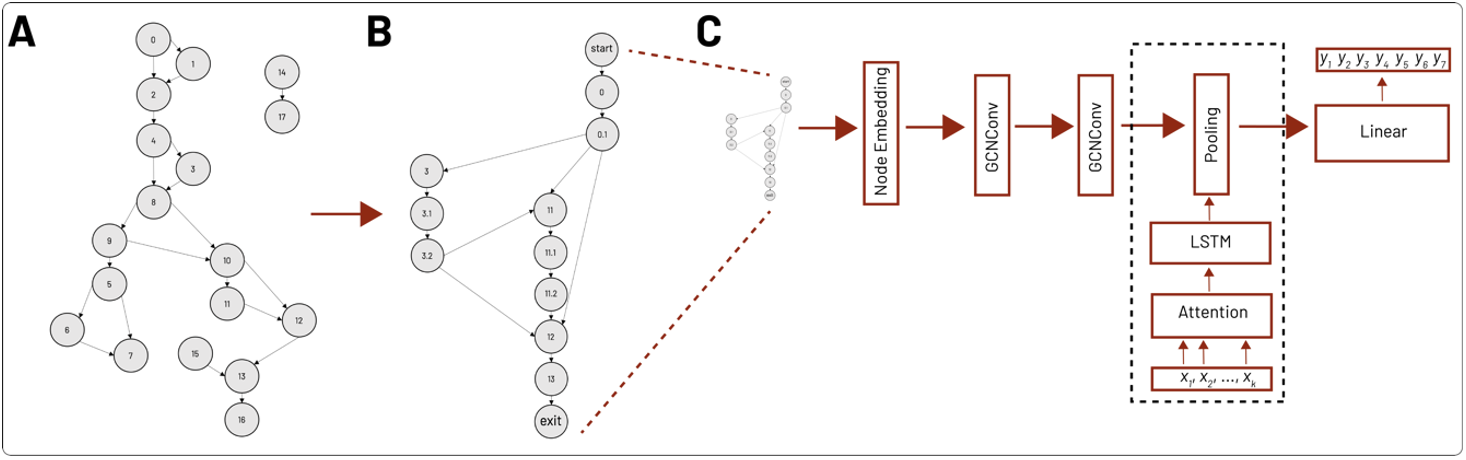
We also considered CFG output from IDA (see Figure 1A) as a separate input representation, where nodes represent functions’ basic code blocks and edges represent control flow instructions like branches or loops between blocks. As with Nero, we obtained CFGs from disassembled functions, reconstructed call site graphs for each call instruction, and learned sequences of call sites using several competing models including a Graph Convolutional Network (GCN). In contrast to Nero, we did not augment call site graphs with additional argument source information. We refer to our malware-based GCN model as CFG2Seq.
To adapt the Nero architecture for malware function disassembly, we first reduced each corresponding CFG appropriately to only include selected call site nodes. Call site nodes are nodes associated with API calls in the CFG. For example, the initial CFG in Figure 3A reduces to the call site graph shown in Figure 3B. In Figure 3C, the reduced graphs were subsequently used as input to train a GCN, which consisted of learned API call embeddings, followed by 2 layers of graph convolutions (i.e. GCNConv) and a Set2Set graph pooling layer (dotted rectangle, where k refers to the number of nodes) to summarize the graph. The pooled representation was then fed to a linear decoder to predict a sequence of up to 7 output tokens per function.
Methods and Results
Our input dataset consisted of over 360k disassembly functions and corresponding annotations extracted from 4.3k malicious PE files. Function representations and annotations were de-duplicated by depth-first hashing of internal AST nodes, and subsequently split into 80% train, 10% validation, and 10% test sets following the procedures outlined in both code2seq and Nero. Our annotations came from a combination of auto-generated IDA function names and a proprietary database of stored metadata representing about a decade’s worth of descriptive function names authored by Mandiant reverse engineers. Raw annotation strings were tokenized into individual words, and care was taken to normalize and merge tokens to account for the variability in annotation quality between analysts.
We quantitatively evaluated our models by computing precision, recall, and F1 scores on holdout splits and observed that the best performing model using our PE test set was the type-enhanced code2seq model (bold, Table 1). The first three rows of Table 1 display the metrics as reported within the code2seq and Nero papers, whereas the last three rows display the metrics as measured from our test set. Since different datasets were used, direct model performance comparisons are not applicable. However, we can observe that our models achieve test scores within a similar range as the previously published ones, indicating value in our novel approach despite applying these methods to lower-level programming languages disassembled from malicious PE files.
| DATASET | MODEL | PRECISION | RECALL | F1 |
| Java-med | code2seq | 51.38 | 39.08 | 44.39 |
| Java-med | code2seq (type-enhanced) | 49.15 | 42.35 | 45.50 |
| GNU ELF | Nero | 48.61 | 42.82 | 45.53 |
| PE Test (Ours) | code2seq | 55.68 | 55.70 | 55.69 |
| PE Test (Ours) | code2seq (type-enhanced) | 62.12 | 61.10 | 61.60 |
| PE Test (Ours) | CFG2Seq | 55.07 | 43.49 | 48.60 |
Next, we had two reverse engineers independently annotate functions from several disassembled malware samples mentioned in the popular book Practical Malware Analysis (PMA). Table 2 shows the type-enhanced code2seq model prediction in the first column and the analyst annotations in the subsequent columns. Notice the differences in annotation patterns between columns A and B; sometimes one analyst annotated a function, and the other did not, and sometimes they might have agreed on what to label a function but used entirely different naming conventions or levels of descriptive granularity. Analyst selectivity and syntactic variability are both common problems for which our modeling provides a unified solution.
In Table 2, it’s clear that the type-enhanced code2seq model can account for a variety of code abstraction levels, including high-level API usage patterns, data processing patterns like encoding and decoding, as well as low level library operations and trivial API wrappers. The model often successfully predicts many more useful function annotations even in this more difficult evaluation setting where the analyst has no prior knowledge of the model’s predictions. In practice, these predictions will be even more useful in a guided analyst setting where a reverse engineer has access to recommended annotation model predictions in real-time as they’re triaging a given malware sample.
| MODEL PREDICTION | ANALYST A | ANALYST B |
| ['execute', 'self', 'delete', 'self'] | _delete_myself | selfdel |
| ['get', 'sedebug', 'priv'] | has_priv | grant_priv |
| ['get', 'string', 'name'] | _parsecmd | |
| [‘aes’, ‘decrypt’] | likely_rijndael_routine | |
| [‘tolower’] | tolower_wrapper | |
| ['get', 'reg', 'value', 'keys'] | vmcheck_reg_devices | |
| ['inject', 'into', 'process'] | process_replacement | |
| ['zb64', 'decode'] | _base64_decode_probably | b64_decode |
| ['create', 'shell', 'thread', 'shell'] | RevShell | |
| ['start', 'main', 'thread'] | DllMainThreadStart | |
| ['dobase64'] | _base64_encode | b64encode3 |
| ['get', 'http', 'post'] | readFromUrl | |
| ['xor', 'data'] | _xor_cipher | decode |
| ['do', 'toupper', 'ctype', 'std'] | _all_toupper | ucase |
| ['get', 'system', 'directorya'] | _get_system_directory | |
| ['get', 'module', 'file', 'name'] | _get_module_file_name | getModuleNameWrapper |
| ['create', 'dib', 'window'] | _generate_bitmap | CaptureScreenshot |
| ['get', 'rand', 'file', 'name'] | boolean_instr_func | |
| ['load', 'resource', 'by', 'name'] | checkmac | |
| ['get', 'random', 'type'] | _vmchk | vmcheck_in_vx |
| ['rl', 'stream', 'load', 'from', 'file'] | _encrypt_aes_maybe | cryptoRoutine |
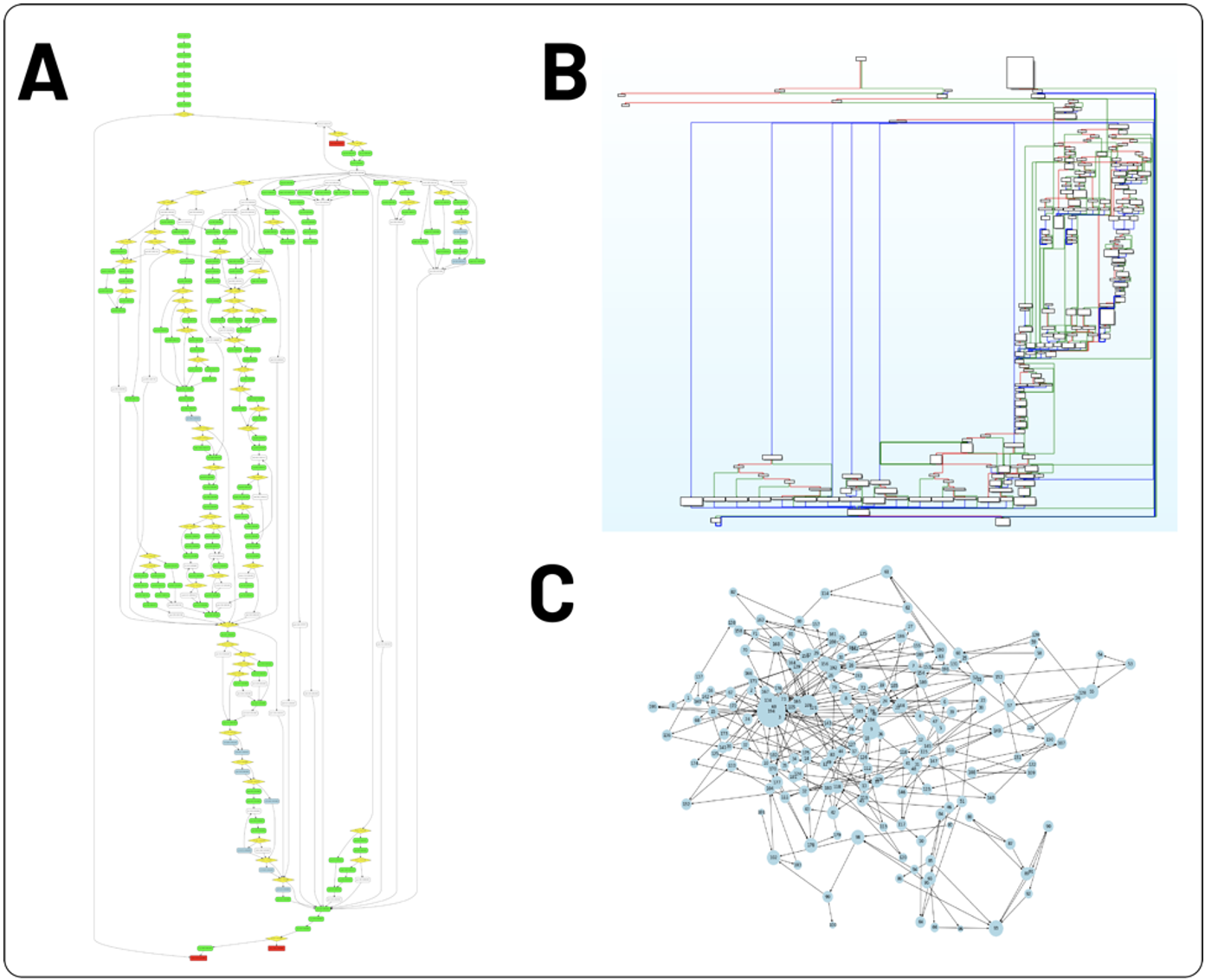
Finally, we demonstrated the applicability of our model on a real-world example that was not recognized by IDA Pro's off-the-shelf signatures. The function’s sheer complexity is evident from Figure 4A’s FIDL’s AST visualization of this function, Figure 4B’s corresponding IDA block diagram representation, and Figure 4C’s corresponding CFG as depicted by NetworkX. This function is not relevant for most analyses and an analyst would not want to spend time reverse engineering it due to its benign and uninteresting nature. The type-enhanced code2seq model predicts the annotation for this function whose ground truth name is _output as [‘str’, ‘conv’, ‘format’, ‘uint’], offering a strong clue that despite its complexity, this function is responsible for mundane format conversion of data types. Instead of keeping track of this complex function’s register values and memory assignments, an analyst can save time and simply move on to the next one after inspecting the prediction from our model.
_outputConclusion
In this blog post, we introduced a few different machine learning models that learn to annotate function names from PE malware disassembly. The proposed NMT models can be useful as either standalone disassembler plug-ins or as conditional components within Mandiant’s scalable malware analysis pipelines. This work represents a collaboration between the MDS and FLARE teams, which together build predictive models to help find evil, automate expertise, and deliver intelligence as part of The Mandiant Advantage Platform. If you are interested in this mission, please consider applying to one of our job openings.
Prepare for 2024's cybersecurity landscape.
Get the Google Cloud Cybersecurity Forecast 2024 report to explore the latest trends on the horizon.