



















Fuzzing Image Parsing in Windows, Part Four: More HEIF
Continuing our discussion of image parsing vulnerabilities in the Windows HEIF codec, we take a look at analyzing a new crash, reconstructing function symbols, and the root cause analysis of the vulnerability, CVE-2022-24457. This vulnerability is present on a default install of Windows 10 and 11 and only requires browsing to a folder containing the malicious image file to trigger the vulnerability. The vulnerability is triggered when Windows attempts to automatically generate a thumbnail for the image. All vulnerabilities have been remediated by Microsoft following the disclosure by Mandiant.
The Crash - CVE-2022-24457
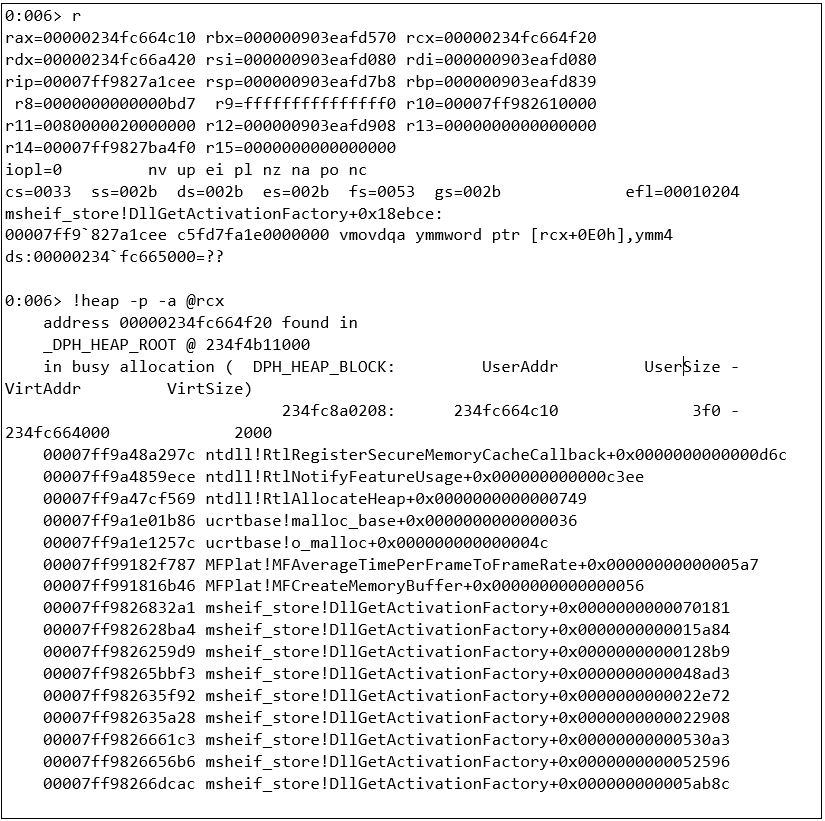
The crash in Figure 1 is an out of bound memory write within an AVX2 instruction; note that the crash function is considerably large and contains a notable series of AVX2 instructions. After a quick look around the decompilation, the operations, and internal calls to memcpy functions, we can deduce this as an AVX2 optimized version of memcpy. An out-of-bounds write inside the memcpy function is a good crash for further analysis.
Identifying other functions
With the crash function identified as memcpy, we next try to identify other functions in the binary. For this, we go one frame up the call stack and look at the decompilation in Figure 2. We can see that this decompliation contains a call to sub_18017dd88, which appears to be a logging function with the function name as its second parameter.
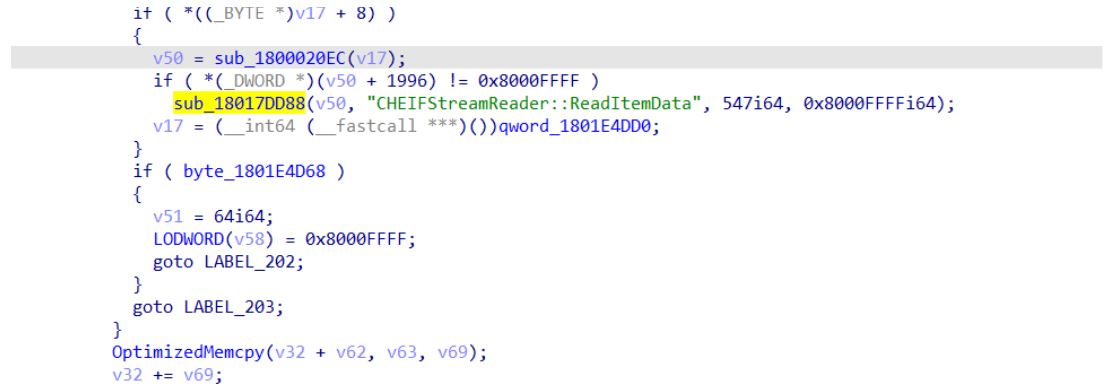
Some software ships with logging capabilities which can be helpful for analyzing crashes and performance issue in a production environment. In this case, the logging calls can help us to reconstruct multiple function names and understand the implemented functionality of these functions, which in turn helps us to easily determine the root cause of vulnerabilities. Looking at the cross references, we can see over 5000 calls to this logging function (see Figure 3).
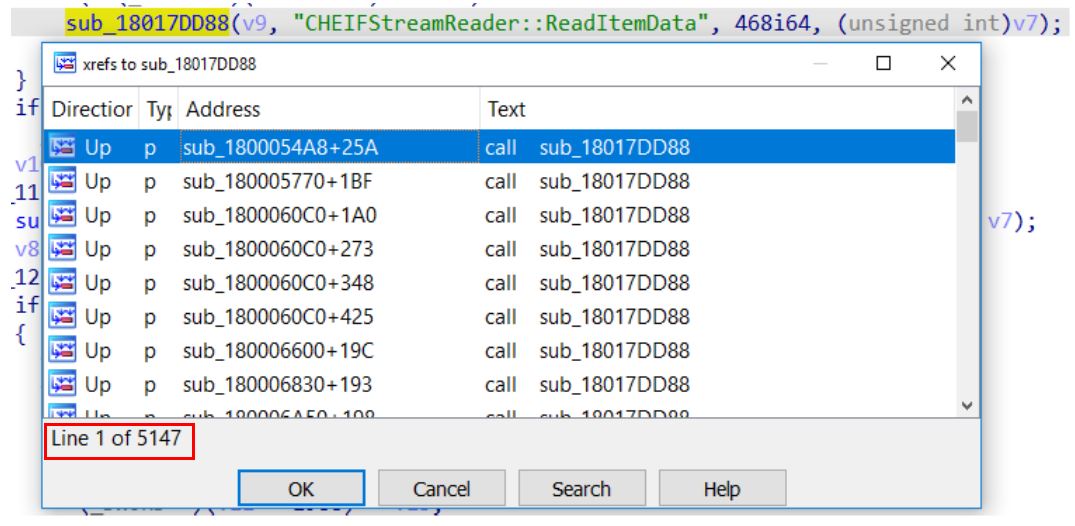
Given the large number of logging calls, we write a script which recovers the function names from the second argument and renames the caller functions.
The IDA Script
An IDAPython script was written to automate the process. It works according to the following algorithm.
- Get list of cross references (xrefs) to the logging function
- Get unique caller functions from the list of xrefs
- Decompile each caller
- Find the logging function call and retrieve the second argument as the function name
- Rename the caller function with the retrieved function name
I decided to write a generic script which can be reused in other projects. For that, I used IDA’s decompiler API to avoid processor and calling convention specific code. The script also makes use of our decompiler wrapper FIDL. The script is provided in Table 1.
from idc import * # f_name: The logging function name callers = set() rename('sub_18017DD88', 1) |
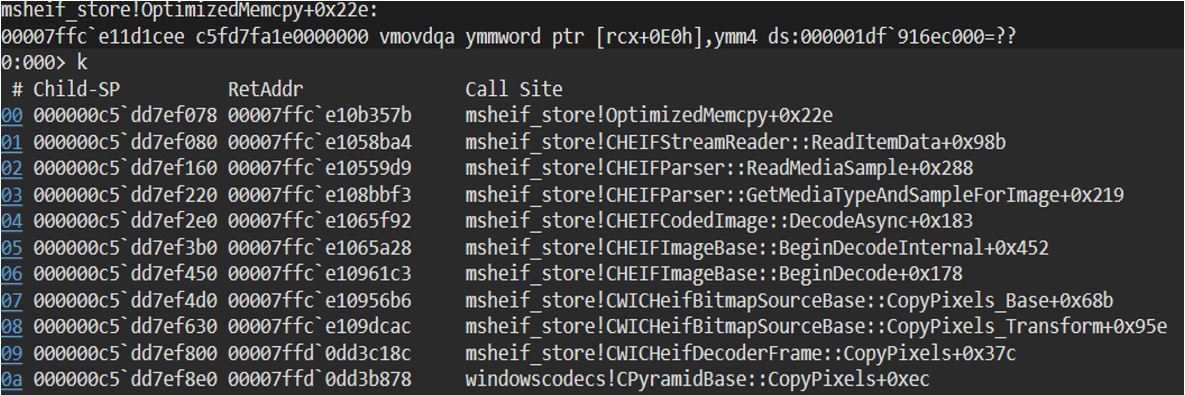
With thousands of functions renamed in IDA, it gets considerably easier to do a full root-cause analysis. Even though we use IDA for static analysis, WinDBG + Time Travel Debugging (TTD) is regularly used for most of the dynamic analysis. We port our renamed symbols into WinDBG by using an IDA plugin: FakePDB. FakePDB creates a PDB from the IDA database, which can be loaded in WinDBG to enhance our debugging/tracing capabilities. An example is shown in Figure 4.
Root cause analysis of the bug
The relevant code from the function msheif_store!CHEIFStreamReader::ReadItemData is presented in Table 2.
/* QWORD currentOffset = 0; |
Astute readers will quickly point at the if condition for a possible integer overflow scenario. But in this case, such a scenario is mitigated while calculating the length in CHEIFItemInfoEntry::GetDataSize. The vulnerability is only visible when we look closely at the MFCreateMemoryBuffer function and its parameters. Figure 5 shows the function’s documentation from MSDN.
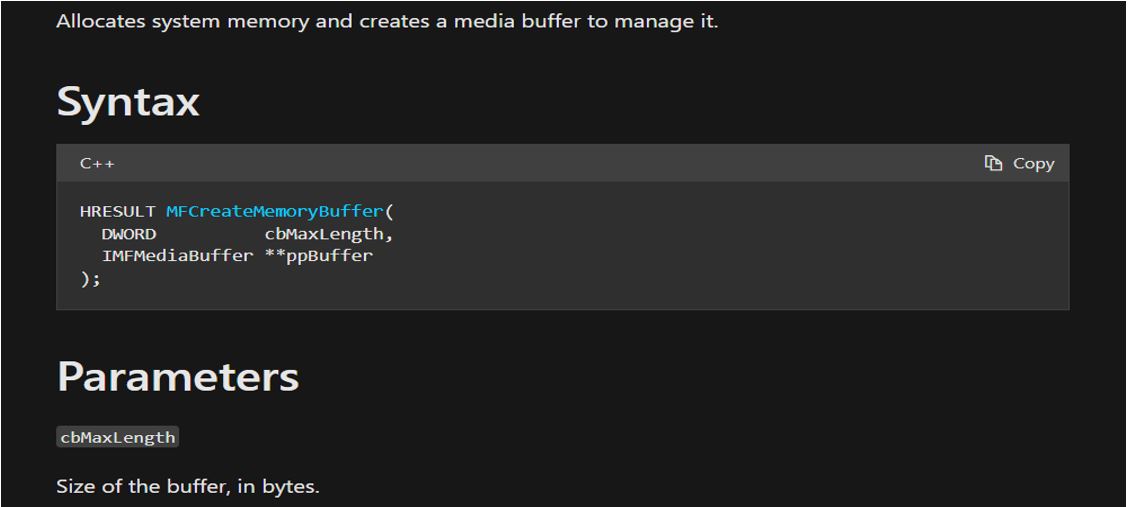
The MFCreateMemoryBuffer function accepts a 32-bit DWORD as the length parameter and returns an allocated buffer. But if we look at Table 2, we can see that the length parameter passed to the function is a 64-bit QWORD. In such an instance, the compiler decides to truncate the QWORD to DWORD. In this case, length 0x1000003f0 gets truncated to much smaller 0x3f0. This allocates a smaller buffer and larger data gets copied into the buffer, causing the out-of-bounds write.
From the function names CHEIFStreamReader::ReadItemData, we guess that the vulnerability occurs while trying to parse the item box. Further backtracing the calls, we see the lengths are read from the function CItemLocationAtom::ParseAtom, which points to the iloc box shown in Figure 6.

Looking at the box content, we can see all the three length values (0x309, 0xEE7 and 0xFFFFF200) specified in the box. Now we can look at the iloc specification to figure out the exact details for those lengths. HEIF is based on ISO Base Media File Format (ISOBMFF) but getting the right specification with box parsing algorithms tends to be complicated or paywalled.
Another approach we can try, is to look at open-source implementations of HEIF image parsers such as libheif or nokiatech-heif. Running our PoC file through decoding routines gives us the exact details of the lengths from the iloc box as shown in Figure 7.
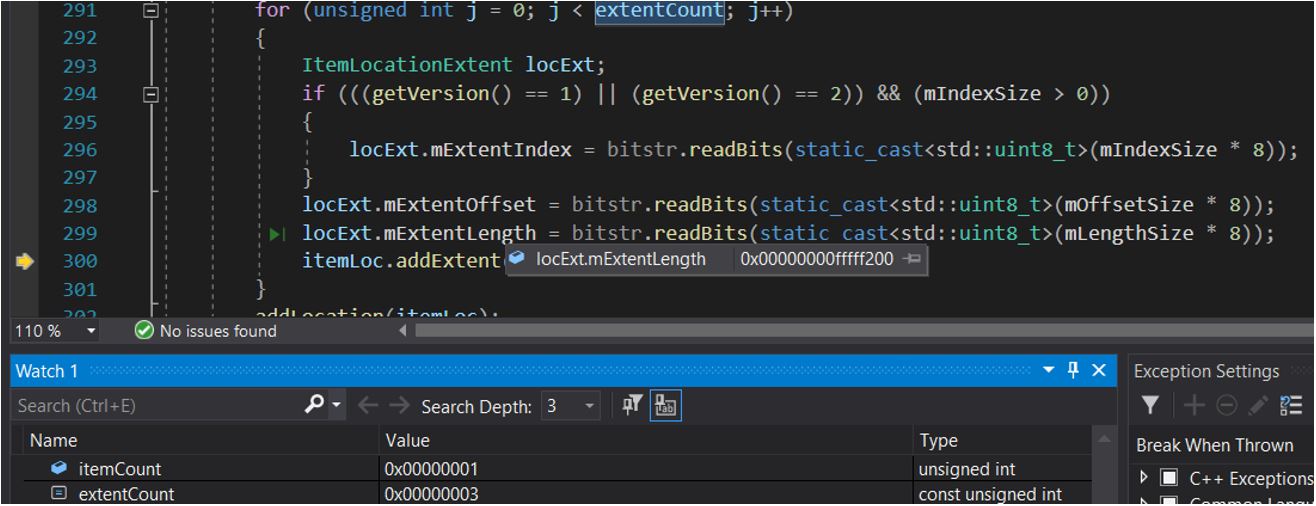
The three lengths we see in our PoC file are called extent lengths. Microsoft’s HEIF implementation reads all the extent lengths and adds them together before the resulting length is used in allocating memory through the API function MFCreateMemoryBuffer. This API truncates the lengths to a DWORD and allocates a smaller buffer, causing the out-of-bounds write.
Patch
Microsoft patched this vulnerability in March 2022 by bailing out with an error if the total length is greater than 0xC8000000 (~3GiB).
Conclusion
Part four of this blog series presents a vulnerability in Microsoft’s HEIF decoder and shows how to reconstruct symbols to do a full root-cause analysis of the vulnerability. A list of latest reported vulnerabilities in HEIF codec can be found in the following appendix and found referenced in the Mandiant Vulnerability Disclosures.
Appendix
CVE id | Submitted Date | Fixed Date | Vulnerability type |
CVE-2022-22007 | 22-April-2021 | 08-March-2022 | Heap overflow |
CVE-2022-21926 | 13-September-2021 | 08-February-2022 | Heap overflow |
CVE-2022-21917 | 17-September-2021 | 11-January-2022 | Heap overflow |
CVE-2022-21927 | 17-September-2021 | 08-February-2022 | Heap overflow |
CVE-2022-22006 | 17-September-2021 | 08-March-2022 | Heap overflow |
CVE-2022-21844 | 23-September-2021 | 08-February-2022 | Heap overflow |
CVE-2022-24453 | 19-October-2021 | 08-March-2022 | Heap overflow |
CVE-2022-24457 | 19-October-2021 | 08-March-2022 | Heap overflow |
CVE-2022-24456 | 14-November-2021 | 08-March-2022 | Heap overflow |
CVE-2022-24532 | 04-December-2021 | 12-April-2022 | Heap overflow |
Prepare for 2024's cybersecurity landscape.
Get the Google Cloud Cybersecurity Forecast 2024 report to explore the latest trends on the horizon.