



















Dynamic capa: Exploring Executable Run-Time Behavior with the CAPE Sandbox
We are excited to announce that capa v7.0 now identifies program capabilities from dynamic analysis reports generated via the CAPE sandbox. This expansion of capa’s original static analysis approach allows analysts to better triage packed and obfuscated samples, and summarizes (malware) capabilities in sandbox API traces. The newest capa release binaries and source code are available at our GitHub page.
This feature was implemented by Yacine Elhamer (@yelhamer) as part of a Google Summer of Code (GSoC) project that the Mandiant FLARE team mentored in 2023. To learn more about the program and our open-source contributors check out the introductory post.
The new version of capa also integrates with Ghidra, NSA’s open source reverse engineering tool. Support for Ghidra was also added as part of a GSoC project by Colton Gabertan and it will be detailed more in an upcoming blog post.
CAPE + capa = <3
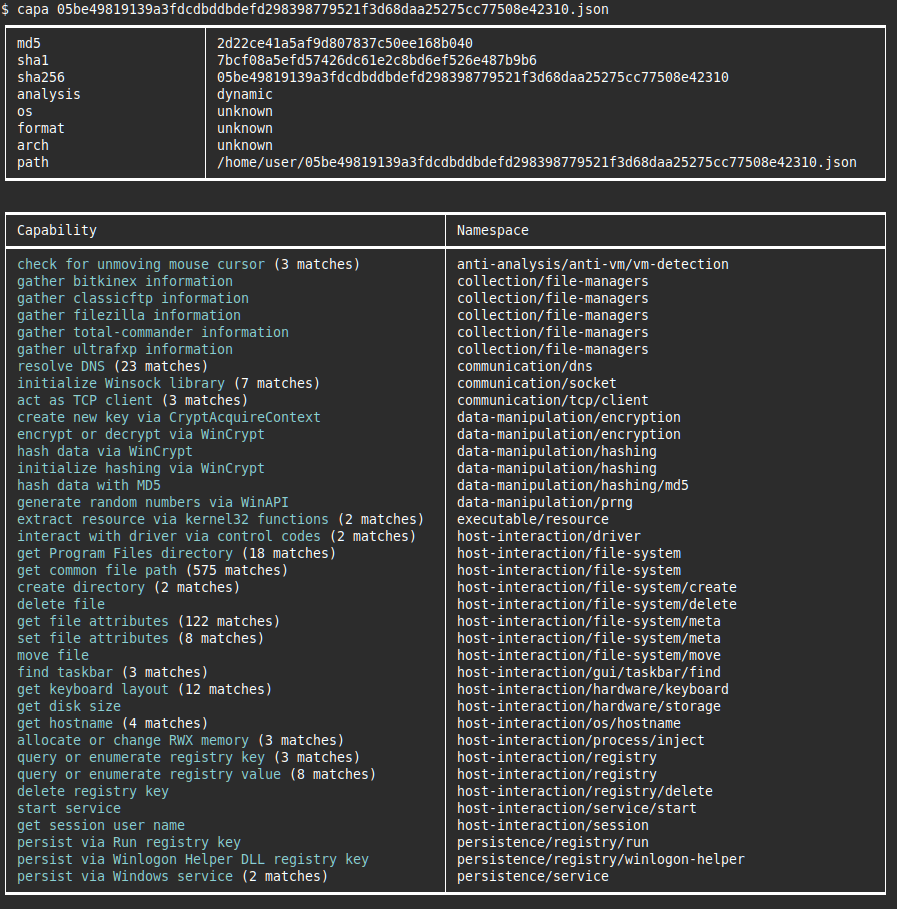
Figure 1 shows an example of running capa v7.0 on the CAPE sandbox results of a UPX-packed sample. Processing dynamic analysis reports circumvents limitations that static analysis has for obfuscated and packed samples.
In this example capa extracts and abstracts the most relevant capabilities from thousands of data points including 7,390 traced API calls. We envision this to speed up sandbox-based malware triage significantly by shortcutting the process of sifting through API logs manually.
The capability detections are based on the same rules that expert malware analysts have contributed over the last three years.
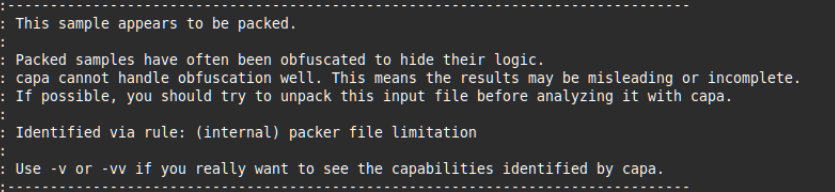
In contrast, Figure 2 shows the static analysis output with limited usefulness because the sample is packed.
Benefits of dynamic analysis
Previous versions of capa relied solely on static analysis for extracting capabilities from programs. This hindered the tool’s ability to handle packed or obfuscated samples well, since the actual program logic and control flow is hidden and not easily examined. It can also take a long time to statically analyze (and disassemble) obfuscated or large programs.
These limitations can be overcome via dynamic analysis, i.e., by using sandboxes. capa now processes sandbox analysis reports that allows the tool to handle packed and obfuscated samples. In addition, these changes enable analysis of multi-stage malware samples that unravel themselves at run-time.
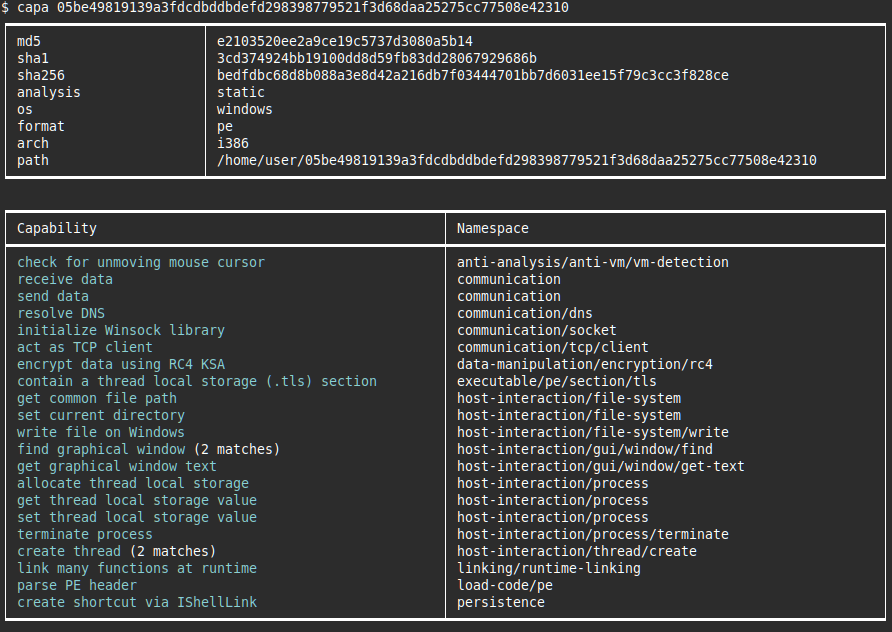
To demonstrate this, we have unpacked the aforementioned sample used and fed it to capa for capability extraction. The results of static analysis against the unpacked malware sample can be observed in Figure 3. Although the sample has been unpacked, we still get fewer results than when analyzing the sample’s associated CAPE report (Figure 1). This is because the malware executes code that is not available during static analysis, but which can be observed dynamically by the CAPE sandbox. So, analyzing sandbox traces using capa can provide further insight into program capabilities.
Dynamic analysis powered by CAPE
We chose CAPE because it’s open-source, provides extensive reports, and is widely used. Several CAPE report datasets are readily-available online (for example Avast’s CAPE reports dataset).
To use the new dynamic analysis functionality, users:
- Analyze a sample using CAPE
- Acquire the CAPE results in JSON format
- Run capa on the CAPE JSON report
capa will automatically identify the sandbox format, and then extract capabilities from the report using its detection rules written by experts around the world.
Figure 4 shows another example of capa’s results on a CAPE sandbox report. The sample is a UPX-packed dropper that writes a file from its resource section to disk and creates a service to persist on the system.

In the future we envision supporting more sandboxes and other dynamic analysis tools such as time travel debuggers (TTD). If you want to contribute to these efforts, please see the Contributing section for more details.
Adding dynamic analysis support to capa
Several changes to capa’s core were required to add dynamic analysis support to capa – most notably the feature extraction process and how capa uses rules. For the technically interested, the following sections outline the major structural changes we made.
Static and dynamic analysis flavors
Since capa was originally designed to be a static analysis tool it did not support analysis in run-time contexts such as processes or threads. To maintain backwards compatibility, we introduced an analysis flavor concept. This isolates the static from the dynamic line of reasoning. When you run capa, it will solely analyze the file according to the appropriate flavor.
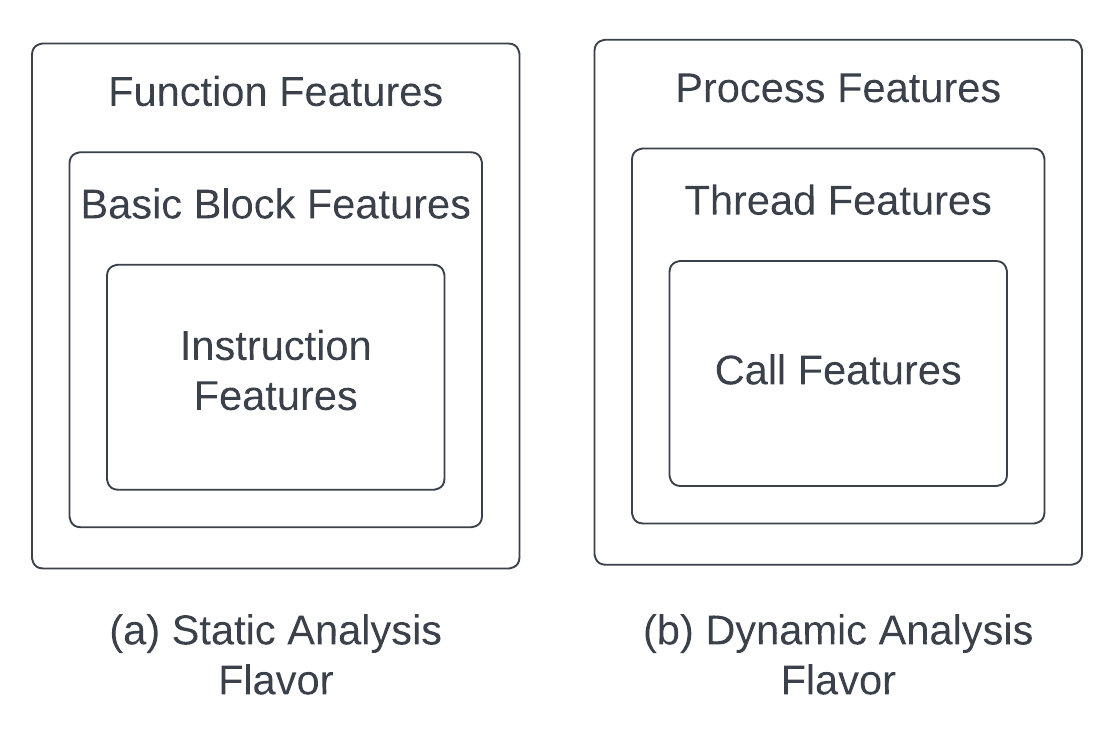
capa extracts features from samples and matches them against rules at different levels. We call these “scopes”. In our rule set, subscopes allow rule logic to be more focused. Each flavor contains a unique scope hierarchy. Like before, the static analysis flavor includes the scopes function, basic block, and instruction. The dynamic flavor includes the newly added scopes process, thread, and call:
- Call scope: features extracted at the level of each individual API call. This includes API function names and argument values.
- Thread scope: features extracted for each execution thread. This includes the features extracted at the call scope.
- Process scope: features extracted for each process, including all the features extracted from the lower scopes (call and thread).
Figure 5 illustrates the two flavors and their scope hierarchy. The file and global scopes which contain features such as target operating system, architecture, and imports are not shown in the Figure 5 since they are common to both flavors.
New flavor agnostic rule format
To avoid duplicating capa rules across static and dynamic analysis flavors, rules can now cover both flavors. When applying a rule only features for the current analysis flavor are used. For this, a rule’s metadata block must specify a scope for both analysis flavors under the new scopes (plural) key. Scopes replace the old scope (singular) key that always implied static analysis.
This implementation enables capa to reuse most of the existing rules. And rule authors can describe capabilities generically — independent of the analysis flavor.
Figure 6 shows an example of an updated rule. In the static flavor, capa matches at the function scope. In the dynamic flavor, capa matches at the thread scope. No other changes to the rule logic are necessary.
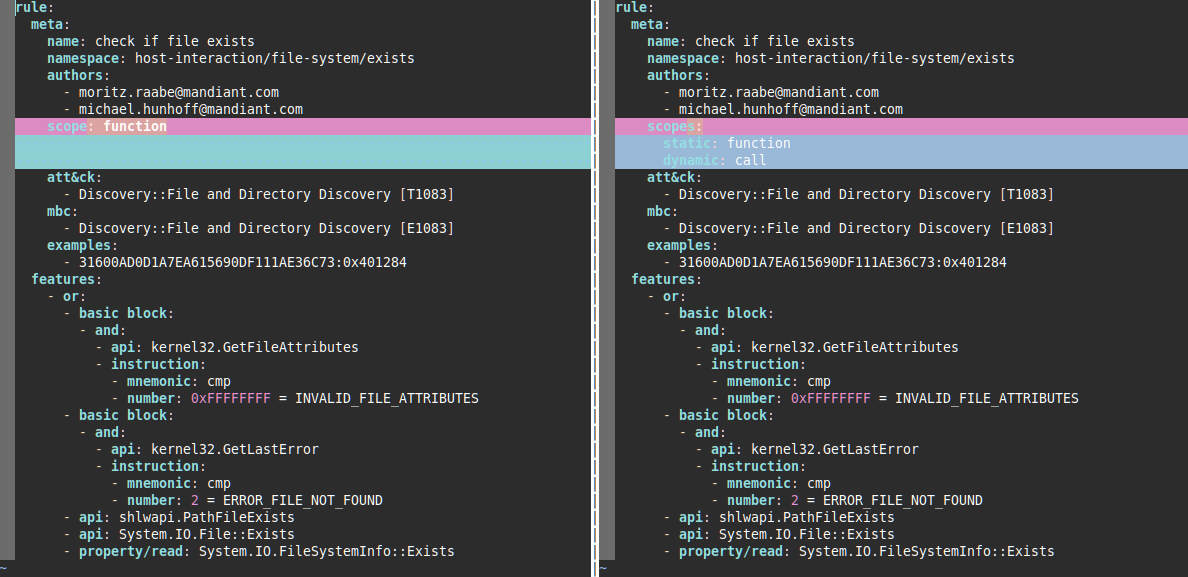
When capa parses this rule, it considers all features and subscopes regardless of the analysis flavor. When performing static analysis all feature combinations are supported. During dynamic analysis the basic block and instruction subscopes, and the property/read feature are not supported. Hence, to match this rule during dynamic analysis, a sandbox report must contain a call to the PathFileExists API (CAPE does not trace .NET API calls like System.IO.File::Exists).
Rule authors need to ensure that their rules can indeed match in all the specified flavors. If a flavor is explicitly excluded a scope can be specified as unsupported. Please refer to the capa-rules documentation for more information on the supported features and subscopes for the static and the dynamic analysis flavor.
Rendering dynamic results
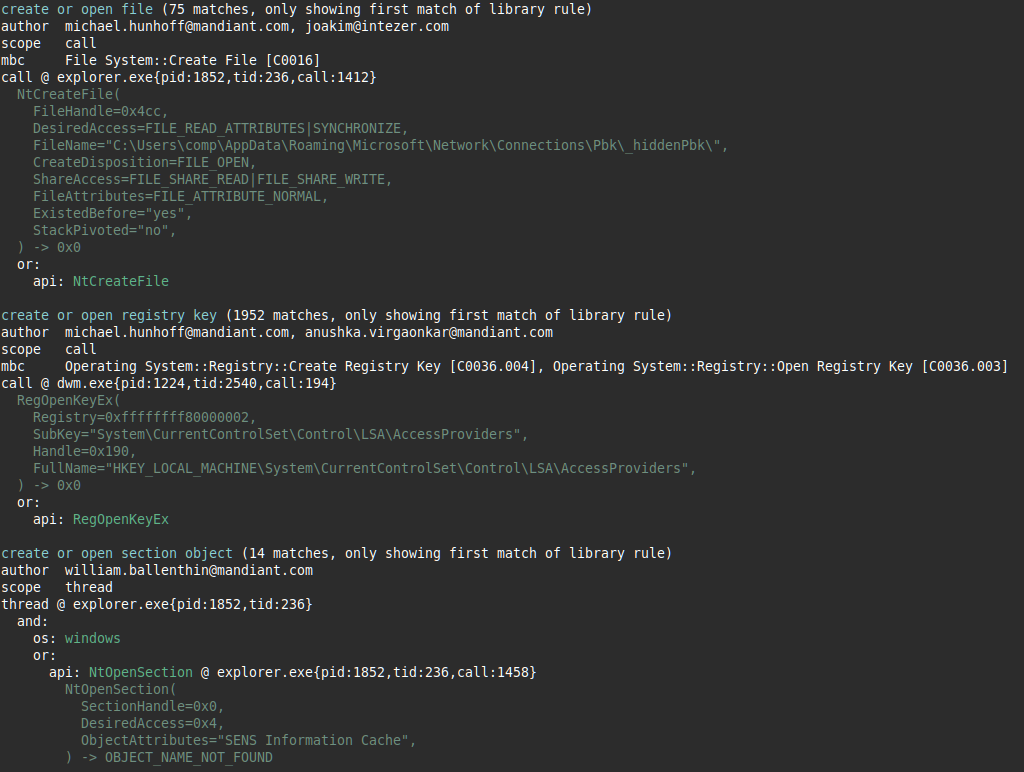
Dynamic analysis provides information that is not available during static analysis (e.g. process names and function call arguments recovered at runtime). To make capa results as informative as possible we have updated capa’s detailed output rendering accordingly. For instance, for extracted API argument values, we provide the associated argument names as defined by CAPE (note that this can differ from Microsoft's MSDN documentation). Furthermore, capa displays the name and identifier of the process, thread, or call where capabilities were detected. Figure 7 shows the very verbose output when analyzing a report available in our test files repository.
Contributing
Dynamic analysis support opens up capa to a multitude of future possibilities. We are extremely excited and would love to work with our community to actualize them! Some of the most pertinent ideas are listed as follows. If you are interested in working on any of the issues or have ideas of your own, please reach out via the following links or create a new GitHub issue.
- Additional sandbox support: We would love to support more sandboxes such as VMRay, Joe Sandbox, or VirusTotal Jujubox. Contributing the core functionality of a new sandbox backend should take about 10-20 hours – depending on your familiarity with the sandbox and capa.
- Time travel debugging: We think it would be possible to build a lightweight “sandbox” that processes TTD traces. This would be helpful for users who create traces as part of their analysis workflow. If you’re interested please see previous discussions and reach out to us.
- Extract host-based and network-based indicators: sandbox traces often include malware indicators. Extracting indicators related to found capabilities could further speed up triage workflows and support analysts.
Conclusion
The new capa release supports sandbox-based dynamic analysis of programs – currently using the CAPE sandbox. This allows the tool to better analyze packed, obfuscated, and very complex samples with potential performance and accuracy improvements. By extracting and abstracting thousands of data points capa can speed up sandbox-based malware triage significantly. We hope you leverage the new possibilities and look forward to hearing your feedback and ideas.
You can find capa’s source code on our GitHub page. To get started, download the standalone binaries for Windows, Linux, and Mac from our Releases page. Alternatively, use pip to install the tool from PyPI using pip install flare-capa. For more details please visit our installation page.
To use capa, you can directly run it against either an executable, shellcode, or a CAPE sandbox report. The tool automatically detects the sample’s format and performs the required analysis. For more details on using CAPE and capa please see the download and usage page on our GitHub page.
Prepare for 2024's cybersecurity landscape.
Get the Google Cloud Cybersecurity Forecast 2024 report to explore the latest trends on the horizon.